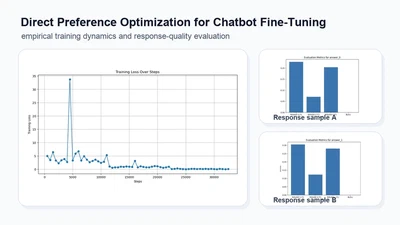
Direct Preference Optimization for Chatbot Fine-Tuning: An Empirical Study
Empirical study of Direct Preference Optimization for chatbot fine-tuning.
Empirical study of Direct Preference Optimization for chatbot fine-tuning.
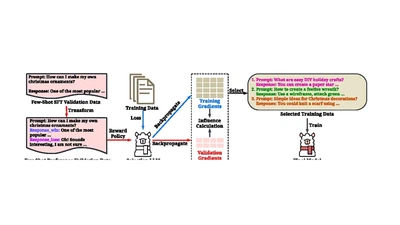
Reward-oriented data selection for task-specific LLM instruction tuning.