Evaluating video models for true multimodal reasoning.
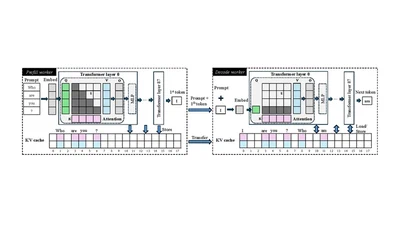
Distributed disaggregated inference for efficient LLM serving.