Efficient Cross-GPU Communication for Disaggregated LLM Serving

I am a research-oriented machine learning systems engineer working on foundation model infrastructure, closed-loop evaluation and optimization systems, and scalable AI platforms. My work focuses on building reliable Model-as-a-Service and Harness-as-a-Service platforms that connect data, training, inference, evaluation, and feedback loops into measurable, continuously improving AI products.
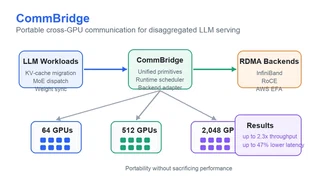
My recent work centers on Model-as-a-Service platforms and high-performance LLM inference. I develop serving infrastructure with vLLM and SGLang across model runtime integration, scheduling and continuous batching, KV-cache and memory management, distributed execution, observability, and reliability. This systems work is closely connected to my research on distributed disaggregated inference, preference optimization, instruction-tuning data selection, multimodal evaluation.
My broader research centers on reinforcement learning infrastructure and reinforcement learning optimization algorithms for scalable AI systems. I am interested in how policy optimization, reward modeling, preference learning, offline RL, simulation environments, distributed rollout systems, and automated evaluation harnesses can be engineered together to improve model behavior. My goal is to build frontier AI systems that learn from feedback efficiently, evaluate progress rigorously, and remain dependable when deployed at scale.