Dezhi Yu
Open Menu
Close Menu
Home
Publications
Service
Experience
Contact
CV
Y. Wu
Large Language Models
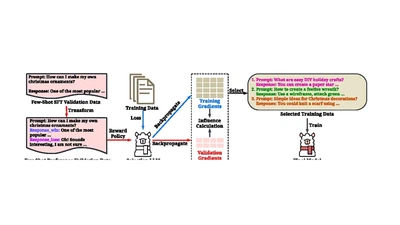
ROSE: A Reward-Oriented Data Selection Framework for LLM Task-Specific Instruction Tuning
Reward-oriented data selection for task-specific LLM instruction tuning.
y.-wu
•
Nov 1, 2025
•
1 min read
Read more